C2D -
Complex Changes in Data evolution
Interpreting evolving data
The wide availability and fast publishing of information give new potential and raise new challenges for data management. An emerging issue concerns collections of data (often scientific) that evolve independently, but remain in some ways interconnected. People in scientific communities need to review how their recorded results have evolved, in order to compare and re-evaluate previous and current conclusions. Such an activity requires a search that moves backwards and forwards in time, across various databanks, since the work of a team depends on results published by other teams. In those cases, simply revising past document snapshots is not enough.
As an example, consider two Web databanks, A and B, maintained by two biology research teams. Databank A is an authority in miRNAs (parts of genes associated with the production of proteins), and many other research teams rely on it to get the most current developments. Knowledge on miRNAs advances rapidly, and A changes often to reflect this. A miRNA in A may change name and properties, split into two distinct miRNAs, merge with another to form a new miRNA, etc. Databank B need to update its content to be in line with A, meaning that experiments may be repeated and processes may be adapted. Researchers using B often need to examine the trail of an object in B across time (data provenance), review the reason behind the changes it went through, and retrieve data associated with specific states of that object.
Our objective is to design methods and implement tools for modeling, storing, querying, synchronizing, and navigating distributed interrelated evolving data.
Changes as complex objects
A key problem in reasoning about data evolution stems from the fact that information systems usually treat changes as distinct events. In reality, a number of changes that occur at disparate and seemingly unrelated pieces of data constitute conceptually a single complex change event. Such high-level changes are more meaningul than the individual changes they encompass, and offer a richer interpretation of the evolution process.
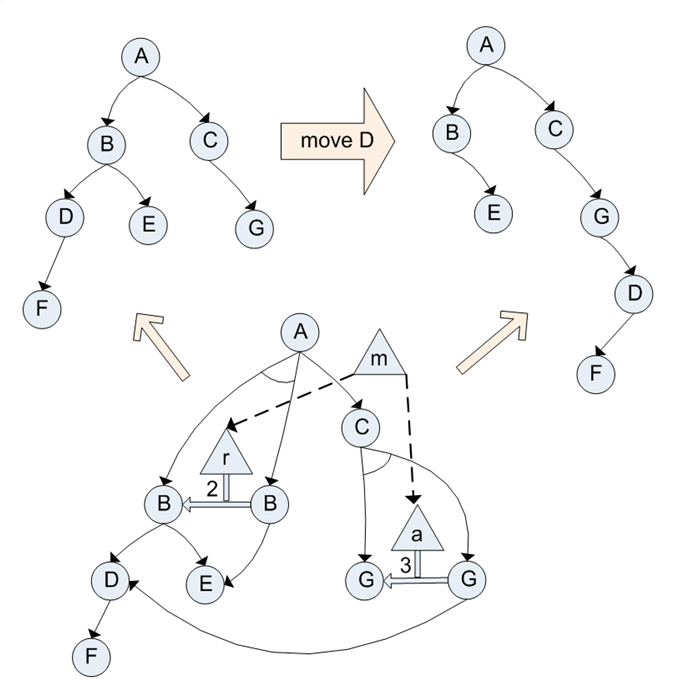
In our approach, changes are discrete objects that have complex structure and retain their semantic and temporal characteristics, rather than being isolated low-level transformations on data. For example, the high-level change operation "move" is a complex object composed by the atomic change objects "remove" and "add".
Information systems that treat changes as first class citizens can provide a better understanding of the evolution and the provenance of data, and can support synchronization between databanks.
Research objectives:
- A model for representing complex change processes.
- A query language for expressing evolution queries.
- Definition of types (templates) for complex changes.
- Synchronization of interrelated data across sources.
- Implementation of tools for recording and querying complex changes.
- Testing with real application scenarios.
- Experimentation and evaluation in terms of modeling complexity, query expressiveness, and efficiency.
People
-
Yannis Stavrakas,
Researcher at IMIS. -
George Papastefanatos,
Post-doctoral fellow at IMIS. -
Theodora Galani,
PhD student.
Publications
- George Papastefanatos, Yannis Stavrakas, and Theodora Galani. Capturing the History and Change Structure of Evolving Data. Fifth International Conference on Advances in Databases, Knowledge, and Data Applications (DBKDA 2013), Seville, Spain, January 2013.
-
Yannis Stavrakas, George Papastefanatos, Theodore Dalamagas and Vassilis Christophides.
Diachronic Linked Data: Towards Long-Term Preservation of Structured Interrelated Information.
International Workshop on Open Data (WOD 2012), Nantes, France, May 2012.

- Yannis Stavrakas, and George Papastefanatos.
Using Structured Changes for Elucidating Data Evolution.
ICDE Workshop on Managing Data Throughout its Lifecycle (DaLi 2011), Hannover, Germany, April 11, 2011.
-
Yannis Stavrakas, and George Papastefanatos.
Supporting Complex Changes in Evolving Interrelated Web Databanks.
Proc. of the 18th International Conference on Cooperative Information Systems (CoopIS 2010), Crete, Greece,
October 27-29, 2010.

-
Yannis Stavrakas, Theodore Dalamagas, and Timos Sellis.
Evolution of Interrelated Data: Users, Problems, and Systems.
1st ERCIM DIS Workshop on large scale and federated information spaces, Paris, May 27, 2009.